
A high level view of security risk on common LLM architectures.
Security considerations for each layer in common LLM architectures.
AI this, ML that, there really is no denying the massive shift of organisations implementing AI based solution in their public facing platforms. Many of us have engaged with some or other chat bot powered by GenAI over the last few years, and as technology folks building these solutions we’re always concerned about security. If you’re not, ignorance is not bliss in this case and security is everyone’s responsibility. Before I jump into explaining things, it should be noted that GenAI was not used to create this post, this is a culmination of learning as I delve into AI Security and Safety research.
What’s Under The Hood of Common LLMs Architectures?
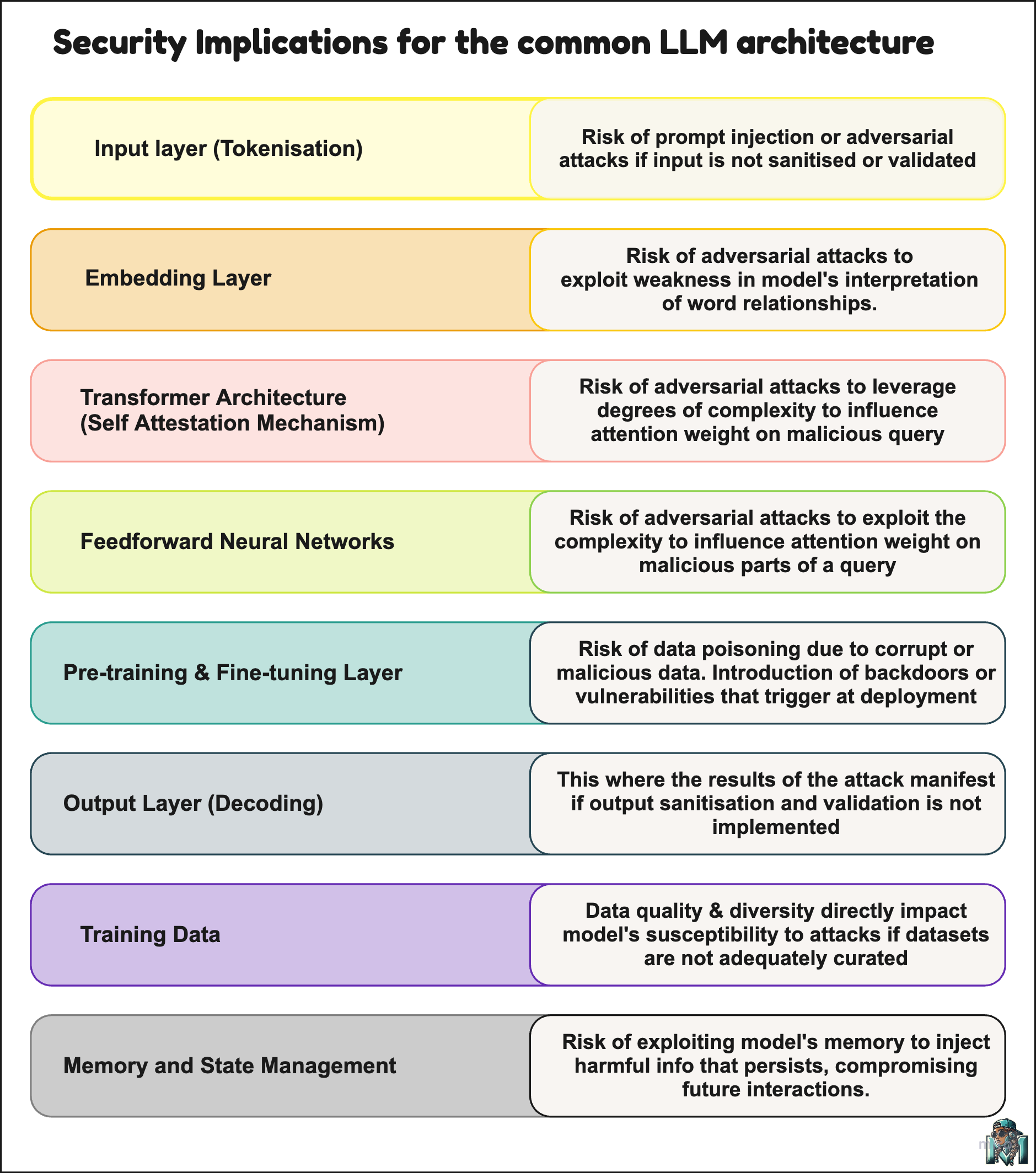
When we break down into the technical components that make the common LLM architecture we have the following layers:
Input Layer - this is where the LLM receives the user input i.e raw text, and converts it into a form that the model understands (tokenisation) by splitting it into smaller units (tokens).
Embedding Layer - this layer converts the tokens into ordered lists of numbers that represent word meanings, numerical vectors, which help the LLMs to understand context and the relationship between words.
Transformer Architecture - this layer adds position information (position encoding) and allows the model to focus on different words based on context (attention).
Feedforward Layer - this layer makes use of many layers of feedforward neural networks that process and refines the input into meaningful output.
Pre-training & Fine-tuning Layer - in the pre-training stage, vast number of datasets are used to train the model on language patterns. In the fine-tuning stage, more targeted datasets are used to refine the model for specific purposes and domains.
Output Layer - this is stage where the model outputs the final prediction in response to the input (decoding).
While technically not layers, these next two items are core components to the architecture :
Training Data - this training data is what teaches the model about language, context, and relationships between words and phrases, and data quality is integral to performance and accuracy.
Memory and State Management - this is similar to traditional memory and state management where context is maintained across multiple interactions to create a more natural experience.
Now that we have the basics mechanics defined, and we’re all on the same level of understanding, let’s get to the potential risks to consider when looking at security.
Security Implication of the Layers - A Visual
Below I have created a simple visual of the aforementioned layers and what security implications we need to cater for at each layer. The purpose of this image is to create a starting point where teams can invest into understanding these risks in the context of their own solutions.
I introduce the various attack vectors that could be introduced or potentially exploited at each layer. The mitigating controls and deep dives into each attack vector is a whole series of blogs that would require more than a Friday evening to compile.
In closing, I hope my sharing what I have been learning and by making it easy to consume these concepts a spark of intrigue is created and you will go down your own journey into understanding how this technology is built, broken and secured.
As always,
Be Kind. Be Brave. Be You.
Mats.
Love it